
DeepSeek 导航网:Ollama 是一个开源的大型语言模型(LLM)本地化部署与管理平台,旨在简化用户在本地运行、管理和交互大模型的流程。它通过提供丰富的预训练模型库、便捷的命令行工具以及跨平台支持,帮助开发者和研究者在无需复杂配置的情况下快速实现模型部署与应用。
Ollama 英特尔优化版,用户可在英特尔 GPU (如搭载集成显卡的个人电脑, Arc 独立显卡等) 上直接免安装运行 Ollama 。支持在多块 GPU 可用时选择特定的 GPU 来运行 Ollama 。
已验证设备
- Intel Core Ultra 处理器
- Intel Core 第 11 至第 14 代处理器
- Intel Arc A 系列 GPU
- Intel Arc B 系列 GPU
Windows 使用方法
步骤 1:下载和解压
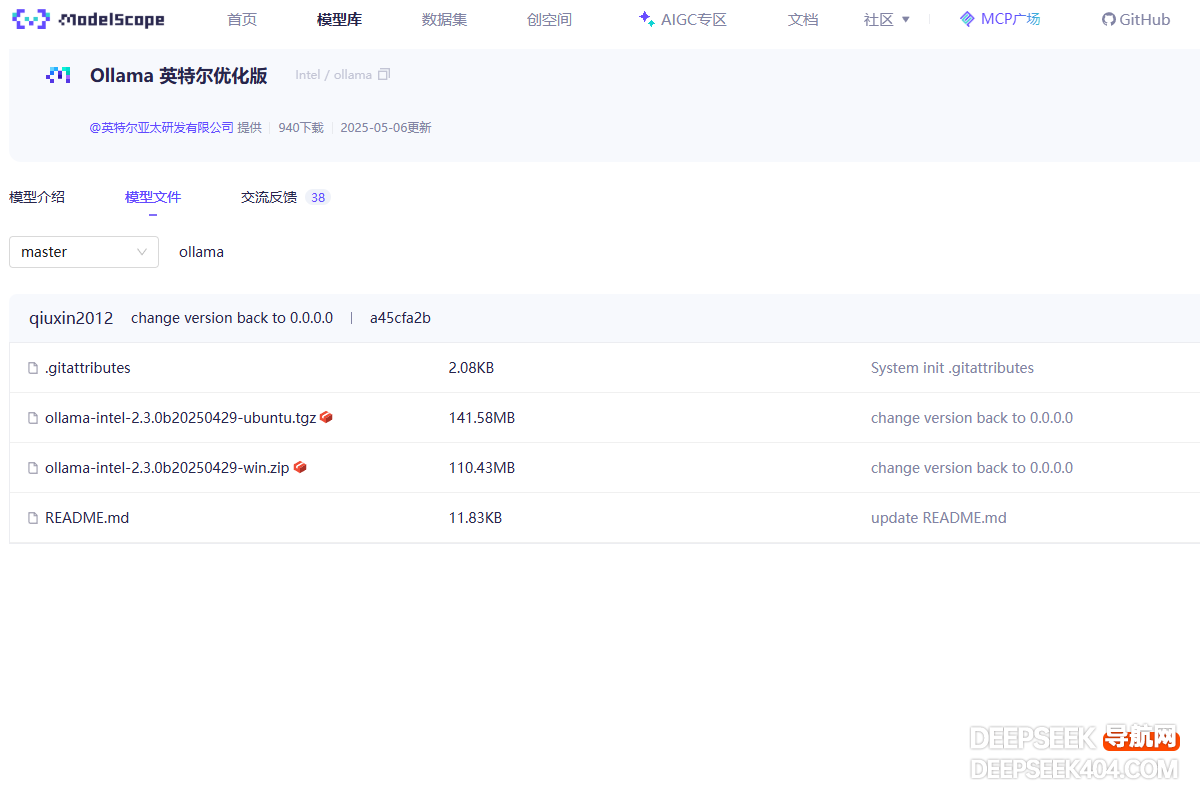
从此处(win 后缀)下载 Ollama 英特尔 Windows 优化版。
然后,将 zip 文件解压到一个文件夹中。
步骤 2:启动 Ollama Serve
根据如下步骤启动 Ollama serve:
- 打开命令提示符(cmd),并通过在命令行输入指令
cd /d PATH\TO\EXTRACTED\FOLDER进入解压缩后的文件夹 - 在命令提示符中运行
start-ollama.bat即可启动 Ollama Serve 。随后会弹出一个窗口
步骤 3:运行 Ollama
接下来通过在相同的命令提示符(非弹出的窗口)中运行 ollama run qwen3:8b(可以将当前模型替换为你需要的模型),即可在 Intel GPUs 上使用 Ollama 运行 LLMs 。
Linux 使用方法
系统环境准备
检查你的 GPU 驱动程序版本,并根据需要进行更新;我们推荐用户按照消费级显卡驱动安装指南来安装 GPU 驱动。
步骤 1:下载和解压
从此处(ubuntu 后缀)下载 Ollama 英特尔 Linux 优化版。
然后,开启一个终端,输入如下命令将 tgz 文件解压到一个文件夹中。
tar -xvf [Downloaded tgz file path]步骤 2:启动 Ollama Serve
进入解压后的文件夹,执行./start-ollama.sh启动 Ollama Serve:
cd PATH/TO/EXTRACTED/FOLDER
./start-ollama.sh步骤 3:运行 Ollama
在 Intel GPUs 上使用 Ollama 运行大语言模型,如下所示:
- 打开另外一个终端,并输入指令
cd PATH/TO/EXTRACTED/FOLDER进入解压后的文件夹 - 在终端中运行
./ollama run qwen3:8b(可以将当前模型替换为你需要的模型)
切换模型下载源
Ollama 英特尔优化版默认从 ModelScope 下载模型。通过在运行 Ollama 之前设置环境变量 OLLAMA_MODEL_SOURCE 为 modelscope 或 ollama,你可以切换模型的下载源。
例如,如果你想运行 deepseek-r1:7b 并且改从 Ollama 库下载,可以通过如下方式切换:
- 对于 Windows 用户:
- 打开命令提示符通过
cd /d PATH\TO\EXTRACTED\FOLDER命令进入解压后的文件夹 - 在命令提示符中运行
set OLLAMA_MODEL_SOURCE=ollama - 运行
ollama run deepseek-r1:7b
- 打开命令提示符通过
- 对于 Linux 用户:
- 在另一个终端(不同于运行 Ollama serve 的终端)中,输入指令
cd PATH/TO/EXTRACTED/FOLDER进入解压后的文件夹 - 在终端中运行
export OLLAMA_MODEL_SOURCE=ollama - 运行
./ollama run deepseek-r1:7b
- 在另一个终端(不同于运行 Ollama serve 的终端)中,输入指令
推荐LLM扩展